01.Java基础
Java 基础
JDK 和 JRE
-
JDK 是什么?有哪些内容组成?
JDK 是 Java 开发工具包
-
JVM 虚拟机: Java 程序运行的地方
-
核心类库: Java 已经写好的东西,可以直接用
-
开发工具: Javac、Java、jdb、jhat…
-
-
JRE 是什么?有哪些内容组成?
- JRE 是 Java 运行环境
- JVM、核心类库、运行工具
-
JDK,JRE,JVM三者的包含关系
-
JDK 包含 JRE
-
JRE 包含 JVM
-
运算符
算术运算符
-
隐式转换(自动类型提升)
-
把一个取值范围小的数值,转成取值范围大的数据
-
取值范围: double > float > long > int > short > byte
-
取值范围小的,和取值范围大的进行运算,小的会先提升为大的,再进行运算
-
byte short char 三种类型的数据在运算时,都会直接先提升为 int ,然后再进行运算
1
2
3byte a = 10;
byte b = 20;
数据类型? c = a + b; // a 和 b 为 byte, 在运算时提升为 int, 故此时数据类型为 int.
-
-
强制转换
-
把一个取值范围大的数值,转成取值范围小的数据
-
目标数据类型 变量名 = (目标数据类型) 被强转的数据;
-
-
字符串的 “+” 操作
-
当 “+” 操作中出现字符串时, 这个 “+” 是字符串连接符, 而不是算术运算符了, 会将前后的数据进行拼接, 并产生一个新的字符串
-
连续进行 “+” 操作时, 从左到右逐个执行
-
System.out.println(1 + 2 + "abc" + 2 + 1); // "3abc21"
-
自增自减运算符
-
参与计算: 后缀(a++ 先用后加), 前缀(++a 先加后用)
逻辑运算符
-
普通逻辑运算符: &, |, ^, !
-
短路逻辑运算符: &&, ||
原码反码补码
-
原码
- 十进制数据的二进制表现形式, 最左边是符号位, 0为正, 1为负
- 弊端: 利用原码进行计算时, 如果是正数没有问题, 但如果是负数计算, 结果会出错, 实际运算方向跟正确的运算方向相反
-
反码
- 为了解决原码不能计算负数的问题而出现的
- 正数的反码不变, 负数的反码在原码的基础上, 符号位不变, 数值取反, 0变1, 1变0
- 弊端: 负数运算时, 如果结果不跨0, 没有问题, 但如果结果跨0, 跟实际结果会有1的偏差
-
补码
-
为了解决负数计算时跨0的问题而出现的
-
正数补码不变, 负数的补码在反码的基础上 +1, 另外补码还能多记录一个特殊的值 -128, 该数据在1个字节下, 没有原码和反码
-
计算机的存储和计算都是以补码的形式进行的

-
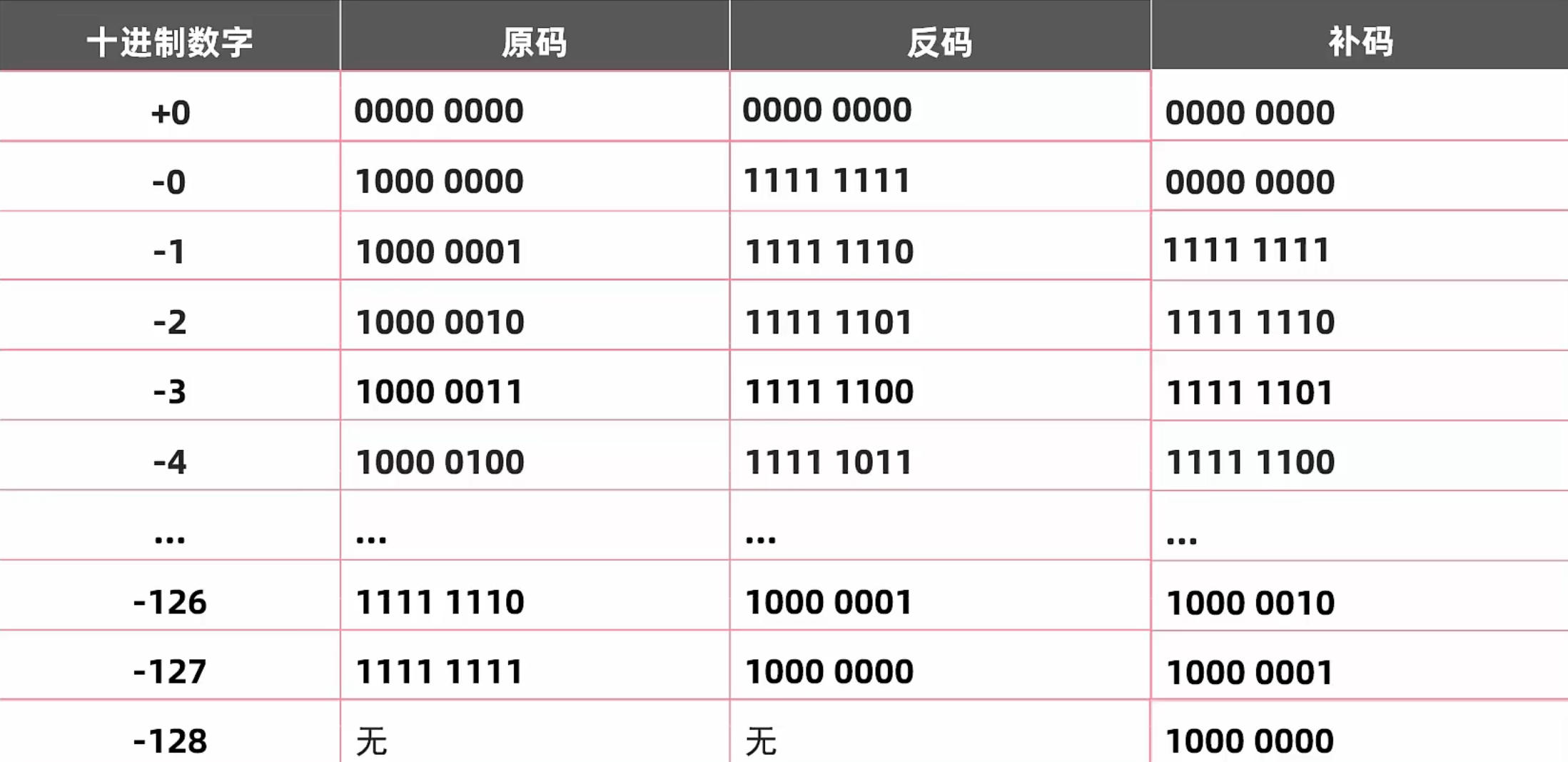
该知识可以解释类型转换
其他运算符
| 运算符 | 含义 | 运算规则 |
|---|---|---|
| & | 逻辑与 | 0为false, 1为true |
| | | 逻辑或 | 0为false, 1为true |
| << | 左移 | 向左移动, 低位补0 |
| >> | 右移 | 向右移动, 高位补0或1(看符号) |
| >>> | 无符号右移 | 向右移动, 高位补1 |
判断和循环
switch
-
default不一定写在最下面, 可写在任意位置, 但仍是最后执行
-
case穿透: 首先会拿小括号中表达式的值跟下面每一个case进行匹配, 如果匹配上了, 就会执行对应的语句体, 如果此时发现了break, 那么结束整个switch语句, 如果没发现break, 那么程序会继续执行下一个case的语句体, 一直遇到break或右大括号为止
JDK12新特性:
2
3
4
5
6
case 1 -> System.out.println("1");
case 2 -> System.out.println("2");
case 3 -> System.out.println("3");
default -> System.out.println("无");
}默认case语句体内有break
-
switch 和 if 的使用场景
- if: 一般用于对范围的判断
- switch: 把有限个数据一一列举出来选择
for 与 while 的区别
-
for 循环中, 控制循环的变量, 因为归属 for 循环的语法结构中, 在 for 循环结束后, 就不能再次被访问到了
-
while 循环中, 控制循环的变量, 对于 while 循环来说不归属其语法结构中, 在 while 循环结束后, 该变量还可以继续使用
数组
初始化
-
在内存中为数组容器开辟空间, 并将数据存入容器中的过程
-
静态初始化
- 数据类型[] 数组名 = new 数据类型[] { 元素1, 元素2, 元素3…}
- 简化后: 数据类型[] 数组名 = { 元素1, 元素2, 元素3…}
- 范例:
int[] array = new int[] {11, 22, 33}; - 简化后:
int[] array = {11, 22, 33};
-
动态初始化
- 数据类型[] 数组名 = new 数组类型[数组长度]
- 范例:
int[] array = new int[3]; - 数组默认初始化规律
- 整数类型: 默认为 0
- 小数类型: 默认为 0.0
- 字符类型: 默认为 ‘/u0000’ (空格)
- 布尔类型: 默认为 false
- 引用数据类型: 默认为 null
地址值
-
数组地址值表示数组在内存中的位置
-
以
[D@776ec8df为例- [ : 表示当前是一个数组
- D: 表示当前数组里面的元素都是double类型的
- @: 表示一个间隔符号 (固定格式)
- 776ec8df: 数组真正的地址值 (十六进制)
遍历数组
-
在 IDEA 自动生成数组的遍历方式:
数组名.fori
内存图
-
栈: 方法运行时使用的内存, 比如 main 方法运行, 进入方法栈中执行
-
堆: 存储对象或者数组, new 来创建的, 都存储在堆内存中
-
方法区: 存储可以运行的 class 文件
-
本地方法栈: JVM 在使用操作系统功能的时候使用, 和我们开发无关
-
寄存器: 给 CPU 使用, 和我们开发无关
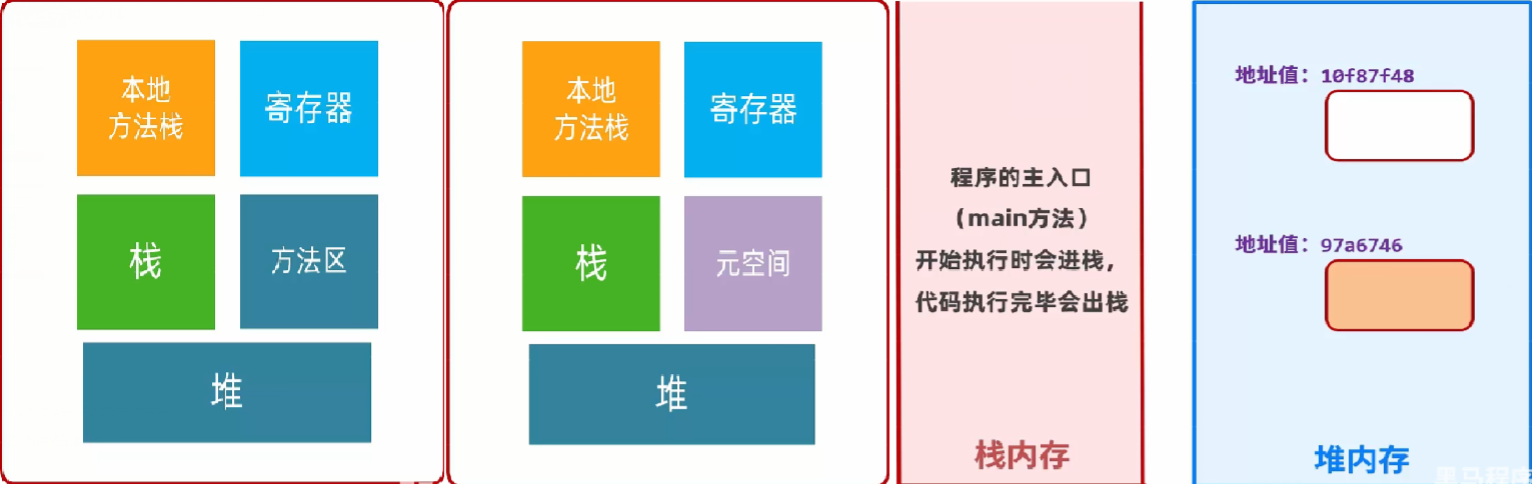
从JDK8开始, 取消方法区, 新增元空间, 把原来方法区的多种功能进行拆分, 有的功能放到了栈中, 有的功能放到了元空间中
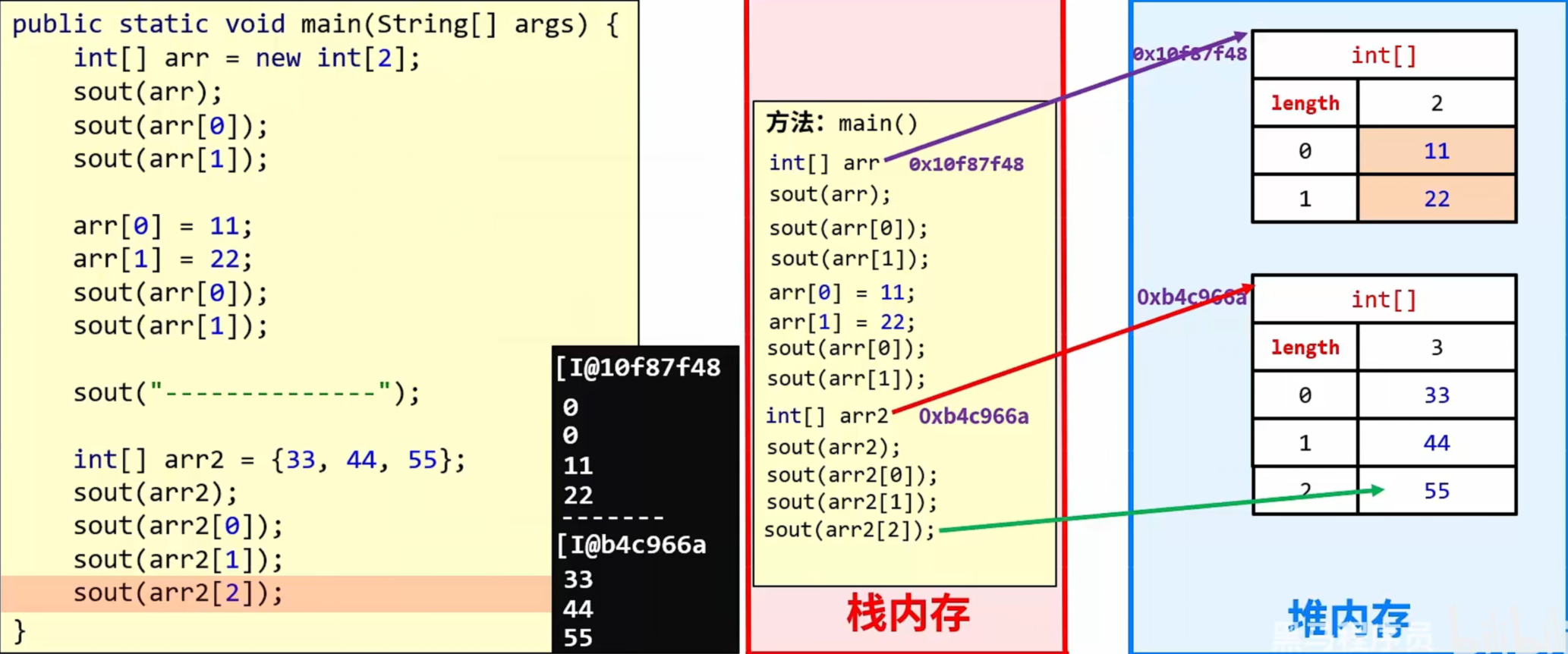
-
当两个数组指向同一个小空间时, 其中一个数组对小空间中的值发生了改变, 那么其他数组再次访问的时候都是修改之后的结果了
拓展: 思考二维数组内存图 (静态初始化, 动态初始化, 动态初始化的两种特例)
方法
程序中最小的执行单元
形参与实参
-
形参: 形式参数, 方法定义中的参数
-
实参: 实际参数, 方法调用中的参数
注意事项
-
方法之间是平级关系, 不能相互嵌套定义
重载
-
在同一个类中, 定义了多个同名的方法, 这些同名的方法具有同种功能
-
每个方法具有不同的参数类型或参数个数, 这些同名的方法构成重载关系
-
同一个类中, 方法名相同, 参数不同的方法. 与返回值无关
- 参数不同: 个数不同, 类型不同, 顺序不同
1
2
3
4
5
6
7
8
9// 不构成重载关系, 因为未满足参数不同这个要求
public class MethodDemo {
public static void fn(int a) {
// 方法体
}
public static int fn(int a) {
// 方法体
}
} -
虚拟机通过参数的不同来区分同名的方法
方法的内存
-
基本数据类型: 整数类型, 浮点数类型, 布尔类型, 字符类型
- 数据值是存储在自己的空间中
- 赋值给其他变量, 也是赋值真实的值
-
引用数据类型: 需要
new创造的- 数据值是存储在其他空间中, 自己空间中存储的是地址值
- 赋值给其他变量, 赋值的是地址值
方法的值传递
-
传递基本数据类型的内存原理
-
传递基本数据类型时, 传递的是真实的数据, 形参的改变, 不影响实参的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class ArgsDemo01 {
public static void main(String[] args) {
int number = 100;
sout("调用change方法前: " + number);
change(number);
sout("调用change方法后: " + number);
}
public static void change(int number) {
number = 200;
}
}
/*
输出结果为:
调用change方法前: 100
调用change方法后: 100
*/
-
-
传递引用数据类型的内存原理
- 传递引用数据类型时, 传递的是地址值, 形参的改变, 影响实参的值
以上内容依据内存图来理解
键盘录入
-
第一套体系
-
nextInt(): 接收整数 -
nextDouble(): 接收小数 -
next(): 接受字符串键盘录入的字符串是
new创建的 -
遇到空格、制表符、回车就停止接收,这些符号后面的数据就不会接受了
-
-
第二套体系
nextLine(): 接受字符串- 遇到空格、制表符可以接收,遇到回车才停止








