03.关系数据库标准语言SQL
SQL概述
结构化查询语言
-
综合统一
-
高度非过程化
-
面向集合的操作方式
-
以同一种语法结构提供多种使用方式
-
语言简洁, 易学易用


基本概念
-
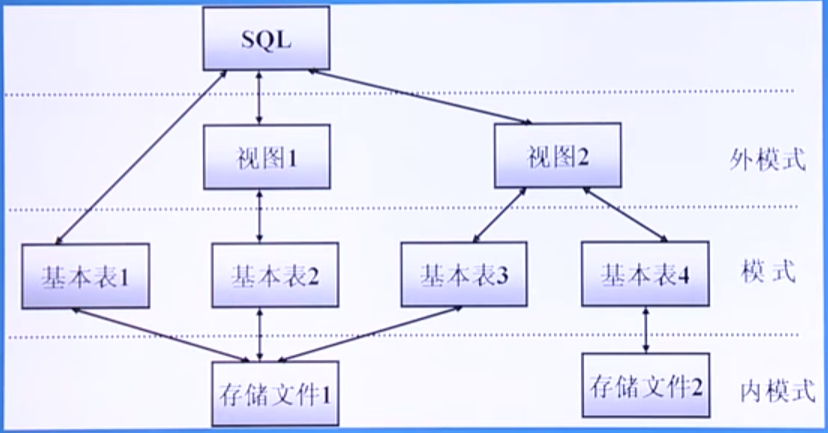
支持三级模式
数据定义
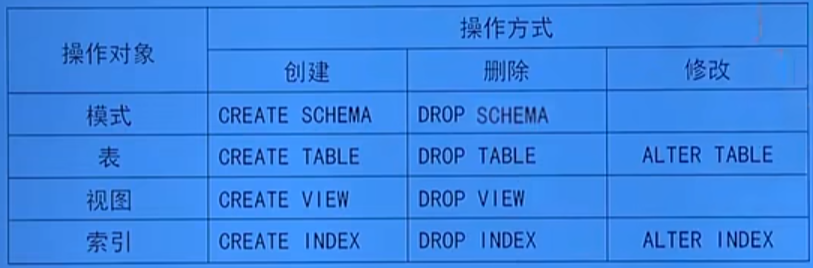
模式的定义与删除
-
定义模式
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>-
在
CREATE SCHEMA中可以接受CREATE TABLECREATE VIEWGRANT子句
-
-
删除模式
DROP SCHEMA <模式名> <CASCADE|RESTRICT>-
CASCADE(级联) -
RESTRICT(限制)
-
基本表的定义, 删除与修改
-
定义基本表
1
2
3
4
5
6CREATE TABLE <表名> (
<列名> <数据类型> [<列级完整性约束条件>]
[, <列名> <数据类型> [<列级完整性约束条件>]]
...
[, <表级完整性约束条件>]
); -
修改基本表
1
2
3
4
5
6
7ALTER TABLE <表名>
[ADD [COLUMN] <新列名> <数据类型> [完整性约束]]
[ADD <表级完整性约束>]
[DROP [COLUMN] <列名> [CASCADE|RESTRICT]]
[DROP CONSTRAINT <完整性约束名> [CASCADE|RESTRICT]]
[ALTER COLUMN <列名> <数据类型>]
; -
删除基本表
DROP TABLE <表名> [RESTRICT|CASCADE]
数据类型
| 数据类型 | 含义 |
|---|---|
| CHAR(n) | 长度为n的定长字符串 |
| VARCHAR(n) | 最大长度为n的变长字符串 |
| INT | 长整数 |
| SMALLINT | 短整数 |
| NUMERIC(p, d) | 定点数, 由p位数字组成, 小数后面有d位 |
| REAL | 取决于机器精度的浮点数 |
| Double Precision | 取决于机器精度的双精度浮点数 |
| FLOAT(n) | 浮点数, 精度至少为n位数字 |
| DATE | 日期, 包含年, 月, 日, 格式为 YYYY-MM-DD |
| TIME | 时间, 包含一日的时, 分, 秒, 格式为 HH: MM: SS |
索引的建立与删除
-
建立索引的目的: 加快查询速度
-
谁可以建立索引: DBA或表的属主(即建立表的人)
-
DBMS一般会自动建立以下列上的索引
- PRIMARY KEY
- UNIQUE
-
谁维护索引: DBMS自动完成
-
使用索引: DBMS自动选择是否使用索引及使用哪些索引
-
建立索引
1
2
3CREATE [UNIQUE] [CLUSTER] INDEX <索引名>
ON <表名>(<列名> [<次序>][, <列名> [<次序>]]...);
# 次序: ASC-升序 DESC-降序-
唯一索引
-
非唯一索引
-
聚簇索引 (CLUSTER) : 索引顺序与表中记录的物理顺序一致的索引组织
- 一个基本表最多只能建立一个聚簇索引
- 经常更新的列不宜建立聚簇索引
- 经常查询的列可以使用聚簇索引
-
-
删除索引
DROP INDEX <索引名>-
删除索引时, 系统会从数据字典中删去有关该索引的描述
-
数据字典
-
关系数据库管理系统内部的一组系统表
-
记录了数据库中所有的定义信息
-
RDBMS执行SQL数据定义时, 实际就是更新数据字典
数据查询
-
语句格式
1
2
3
4
5SELECT [ALL|DISTINCT] <目标列表达式>[, <目标列表达式>]...
FROM <表名或视图名>[, <表名或视图名>]...
[WHERE <条件表达式>]
[GROUP BY <列名1> [HAVING <条件表达式>]]
[ORDER BY <列名2> [ASC|DESC]];
单表查询
-
查询指定列
SELECT <列名> ... FORM <表名> -
查询所有列
SELECT * FROM <表名> -
查询经过计算的值
SELECT <目标列表达式> ... FROM <表名>-
<目标列表达式>- 算术表达式
- 字符表达式
- 单引号括起
- 函数
- 小写 : LOWER()
- 列别名
-
-
选择表中的若干元组
-
消除取值重复的行
- 如果没有指定
DISTINCT关键词, 则缺省为ALL
- 如果没有指定
-
查询满足条件的元组
-
通过
WHERE实现查询条件 谓词 比较 =, >, < , >=, <=, !=, <>, !>, !< 确定范围 BETWEEN AND, NOT BETWEEN AND 确定集合 IN, NOT IN 字符匹配 LIKE, NOT LIKE 空值 IS NULL, IS NOT NULL 多重条件 (逻辑运算) AND, OR, NOT -
字符匹配
- 通配符
- % : 任意长度的字符串
- _ : 占一个字符
LIKE [ESCAPE <换码字符>]- 换码字符后的一个字符要匹配, 不能看作通配符
- 通配符
-
-
-
ORDER BY子句- 按一个或多个属性列排序, 优先级按照列名顺序
-
聚集函数
- 只能用在
SELECT后面 和GROUP BY中的HAVING子句
1
2
3
4
5
6COUNT ([DISTINCT|ALL] *) # 统计元组个数
COUNT ([DISTINCT|ALL] <列名>) # 统计一列中值的个数
SUM ([DISTINCT|ALL] <列名>) # 计算一列值的总和(此列必须是数值型)
AVG ([DISTINCT|ALL] <列名>) # 计算一列值的平均值(此列必须是数值型)
MAX ([DISTINCT|ALL] <列名>) # 求一列值的最大值
MIN ([DISTINCT|ALL] <列名>) # 求一列值的最小值 - 只能用在
-
GROUP BY子句- 按指定的一列或多列值分组, 值相等的为一组, 来细化聚集函数的作用对象
- 未对查询结果分组, 聚集函数将作用于整个查询结果
- 对查询结果分组后, 聚集函数将分别作用于每个组
- 用
GROUP BY分组,SELECT后面只能跟 被GROUP BY的列 和 聚合函数 GROUP BY子句分组后, 可以使用HAVING短语指定筛选条件
- 按指定的一列或多列值分组, 值相等的为一组, 来细化聚集函数的作用对象
-
连接查询
-
等值与非等值连接查询
- 连接查询的
WHERE子句中用来连接两个表的条件称为连接条件或连接谓词- 格式一 :
[<表名1>.]<列名1> <比较运算符> [<表名2>.]<列名2>; - 格式二 :
[<表名1>.]<列名1> BETWEEN [<表名2>.]<列名2> AND [<表名2>.]<列名3>;
- 格式一 :
- 当连接运算符为"="称为等值连接, 其他运算符称为非等值连接
- 自然连接: 若在等值连接中把目标列中重复的属性列去掉则为自然连接
- 连接查询的
-
自身连接
- 需要给表起别名以示区别
-
外连接
- 将主体表中不满足连接条件的元组一并输出
- 左外连接 :
<表名1> LEFT OUT JOIN <表名2> ON - 右外连接 :
<表名1> LEFT OUT JOIN <表名2> ON
-
多表连接
嵌套查询
-
将一个查询块嵌套在另一个查询块的
WHERE子句或HAVING短语的条件中的查询 -
子查询中不能使用
ORDER BY子句 -
带有
IN谓词的子查询1
2
3
4
5SELECT Sno, Sname, Sdept FROM Student
WHERE Sdept IN (
SELECT Sdept FROM Student
WHERE Sname = 'XX'
);-
不相关子查询: 子查询的查询条件不依赖于父查询
-
相关子查询: 子查询的查询条件依赖于父查询
-
-
带有比较运算符的子查询
-
带有
ANY或ALL的子查询 -
带有
EXISTS或NOT EXISTS谓词的子查询
集合查询
-
并操作
UNION -
交操作
INTERSECT -
差操作
EXCEPT
基于派生表的查询
-
子查询还可以出现在
WHERE子句中, 还可以出现在FROM子句中, 此时子查询生成的临时派生表成为主查询的查询对象 -
AS可省略
数据更新
插入数据
-
插入元组
1
2INSERT INTO <表名> [(<属性列1>[, <属性列2>]...)]
VALUES (<常量1>[, <常量2>]...); -
插入子查询结果
1
2INSERT INTO <表名> [(<属性列1>[, <属性列2>]...)]
子查询;
修改数据
1 | UPDATE <表名> |
删除数据
1 | DELETE FROM <表名> [WHERE <条件>]; |
空值处理
-
空值的约束条件
- 属性定义(或者域定义)中有
NOT NULL的约束条件不能取空值 - 加了
UNIQUE限制的属性不能取空值 - 码属性不能取空值
- 属性定义(或者域定义)中有
-
空值运算
- 算术运算 : 空值与另一个值(包括另一个空值)的算术运算的结果为空值
- 比较运算 : 空值与另一个值(包括另一个空值)的比较运算的结果为
UNKNOW - 逻辑运算
视图
-
视图的特点
- 视图是虚表
- 只存放视图的定义, 不存放视图对应的数据
- 表中的数据发生变化, 视图中查询出的数据也随之改变
定义视图
-
建立视图
1
2
3CREATE VIEW <视图名> [(<列名>[, <列名>]...)] AS
<子查询>
[WITH CHECK OPTION]; # 该语句防止在更新视图的时候出错-
组成视图的属性列名: 全部省略或全部指定
-
子查询不允许含有
ORDER BY子句 和DISTINCT短语 -
在对视图查询时, 按视图的定义从基本表中将数据查出
-
-
删除视图
DROP VIEW <视图名> [CASCADE];-
该语句从数据字典中删除指定的视图定义
-
查询视图
-
视图定义后, 用户就可以像基本表一样对视图进行查询了
-
实现视图查询的方法 – 视图消解法
- 进行有效性检查 (即检查视图对应的基本表是否存在)
- 转换成等价的对基本表的查询
- 执行修正后的查询
-
但有些情况下不能正确查询
更新视图
-
一些视图不可更新, 因为对这些视图的更新不能唯一地有意义地转换成对相应基本表的更新
视图的作用
-
简化用户操作
-
对重构数据库提供一定程度的逻辑独立性






